1. Overview
Swift is a data-flow oriented coarse grained scripting language that supports dataset typing and mapping, dataset iteration, conditional branching, and procedural composition.
Swift programs (or workflows) are written in a language called Swift.
Swift scripts are primarily concerned with processing (possibly large) collections of data files, by invoking programs to do that processing. Swift handles execution of such programs on remote sites by choosing sites, handling the staging of input and output files to and from the chosen sites and remote execution of programs.
2. Getting Started
This section will provide links and information to new Swift users about how to get started using Swift.
2.1. Quickstart
This section provides the basic steps for downloading and installing Swift.
-
Swift requires that a recent version of Oracle Java is installed. More information about installing Java can be found at http://www.oracle.com/technetwork/java.
-
Download Swift 0.95 at http://swiftlang.org/packages/swift-0.95.tar.gz.
-
Extract by running "tar xfz swift-0.95.tar.gz"
-
Add Swift to $PATH by running "export PATH=$PATH:/path/to/swift-0.95/bin"
-
Verify swift is working by running "swift -version"
2.2. Tutorials
There are a few tutorials available for specific clusters and supercomputers.
3. The Swift Language
3.1. Language Basics
A Swift script describes data, application components, invocations of applications components, and the inter-relations (data flow) between those invocations.
Data is represented in a script by strongly-typed single-assignment variables. The syntax superficially resembles C and Java. For example, { and } characters are used to enclose blocks of statements.
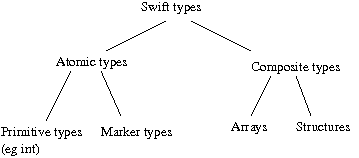
Types in Swift can be atomic or composite. An atomic type can be either a primitive type or a mapped type. Swift provides a fixed set of primitive types, such as integer and string. A mapped type indicates that the actual data does not reside in CPU addressable memory (as it would in conventional programming languages), but in POSIX-like files. Composite types are further subdivided into structures and arrays. Structures are similar in most respects to structure types in other languages. In Swift, structures are defined using the type keyword (there is no struct keyword). Arrays use numeric indices, but are sparse. They can contain elements of any type, including other array types, but all elements in an array must be of the same type. We often refer to instances of composites of mapped types as datasets.
Atomic types such as string, int, float and double work the same way as in C-like programming languages. A variable of such atomic types can be defined as follows:
string astring = "hello";
A struct variable is defined using the type keyword as discussed above. Following is an example of a variable holding employee data:
type Employee{
string name;
int id;
string loc;
}
The members of the structure defined above can be accessed using the dot notation. An example of a variable of type Employee is as follows:
Employee emp; emp.name="Thomas"; emp.id=2222; emp.loc="Chicago";
Arrays of structures are allowed in Swift. A convenient way of populating structures and arrays of structures is to use the readData() function.
Mapped type and composite type variable declarations can be annotated with a mapping descriptor indicating the file(s) that make up that dataset. For example, the following line declares a variable named photo with type image. It additionally declares that the data for this variable is stored in a single file named shane.jpg.
image photo <"shane.jpg">;
Component programs of scripts are declared in an app declaration, with the description of the command line syntax for that program and a list of input and output data. An app block describes a functional/dataflow style interface to imperative components.
For example, the following example lists a procedure which makes use of the ImageMagick http://www.imagemagick.org/ convert command to rotate a supplied image by a specified angle:
app (image output) rotate(image input) {
convert "-rotate" angle @input @output;
}
A procedure is invoked using the familiar syntax:
rotated = rotate(photo, 180);
While this looks like an assignment, the actual unix level execution consists of invoking the command line specified in the app declaration, with variables on the left of the assignment bound to the output parameters, and variables to the right of the procedure invocation passed as inputs.
The examples above have used the type image without any definition of that type. We can declare it as a marker type which has no structure exposed to Swift script:
type image;
This does not indicate that the data is unstructured; but it indicates that the structure of the data is not exposed to Swift. Instead, Swift will treat variables of this type as individual opaque files.
With mechanisms to declare types, map variables to data files, and declare and invoke procedures, we can build a complete (albeit simple) script:
type image;
image photo <"shane.jpg">;
image rotated <"rotated.jpg">;
app (image output) rotate(image input, int angle) {
convert "-rotate" angle @input @output;
}
rotated = rotate(photo, 180);
This script can be invoked from the command line:
$ ls *.jpg shane.jpg $ swift example.swift ... $ ls *.jpg shane.jpg rotated.jpg
This executes a single convert command, hiding from the user features such as remote multisite execution and fault tolerance that will be discussed in a later section.


3.2. Arrays and Parallel Execution
Arrays of values can be declared using the [] suffix. Following is an example of an array of strings:
string pets[] = ["shane", "noddy", "leo"];
An array may be mapped to a collection of files, one element per file, by using a different form of mapping expression. For example, the filesys_mapper maps all files matching a particular unix glob pattern into an array:
file frames[] <filesys_mapper; pattern="*.jpg">;
The foreach construct can be used to apply the same block of code to each element of an array:
foreach f,ix in frames {
output[ix] = rotate(f, 180);
Sequential iteration can be expressed using the iterate construct:
step[0] = initialCondition();
iterate ix {
step[ix] = simulate(step[ix-1]);
}
This fragment will initialise the 0-th element of the step array to some initial condition, and then repeatedly run the simulate procedure, using each execution’s outputs as input to the next step.
3.3. Associative Arrays
By default, array keys are integers. However, other primitive types are also allowed as array keys. The syntax for declaring an array with a key type different than the default is:
<valueType>[<keyType>] array;
For example, the following code declares and assigns items to an array with string keys and float values:
float[string] a; a["one"] = 0.2; a["two"] = 0.4;
In addition to primitive types, a special type named auto can be used to declare an array for which an additional append operation is available:
int[auto] array;
foreach i in [1:100] {
array << (i*2) ;
}
foreach v in array {
trace(v);
}
Items in an array with auto keys cannot be accessed directly using a primitive type. The following example results in a compile-time error:
int[auto] array; array[0] = 1;
However, it is possible to use auto key values from one array to access another:
int[auto] a;
int[auto] b;
a << 1;
a << 2;
foreach v, k in a {
b[k] = a[k] * 2;
}
3.4. Ordering of execution
Non-array variables are single-assignment, which means that they must be assigned to exactly one value during execution. A procedure or expression will be executed when all of its input parameters have been assigned values. As a result of such execution, more variables may become assigned, possibly allowing further parts of the script to execute.
In this way, scripts are implicitly parallel. Aside from serialisation implied by these dataflow dependencies, execution of component programs can proceed in parallel.
In this fragment, execution of procedures p and q can happen in parallel:
y=p(x); z=q(x);
while in this fragment, execution is serialised by the variable y, with procedure p executing before q.
y=p(x); z=q(y);
Arrays in Swift are more monotonic - a generalisation of being assignment. Knowledge about the content of an array increases during execution, but cannot otherwise change. Each element of the array is itself single assignment or monotonic (depending on its type). During a run all values for an array are eventually known, and that array is regarded as closed.
Statements which deal with the array as a whole will often wait for the array to be closed before executing (thus, a closed array is the equivalent of a non-array type being assigned). However, a foreach statement will apply its body to elements of an array as they become known. It will not wait until the array is closed.
Consider this script:
file a[];
file b[];
foreach v,i in a {
b[i] = p(v);
}
a[0] = r();
a[1] = s();
Initially, the foreach statement will have nothing to execute, as the array a has not been assigned any values. The procedures r and s will execute. As soon as either of them is finished, the corresponding invocation of procedure p will occur. After both r and s have completed, the array a will be closed since no other statements in the script make an assignment to a.
3.5. Compound procedures
As with many other programming languages, procedures consisting of Swift script can be defined. These differ from the previously mentioned procedures declared with the app keyword, as they invoke other Swift procedures rather than a component program.
(file output) process (file input) {
file intermediate;
intermediate = first(input);
output = second(intermediate);
}
file x <"x.txt">;
file y <"y.txt">;
y = process(x);
This will invoke two procedures, with an intermediate data file named anonymously connecting the first and second procedures.
Ordering of execution is generally determined by execution of app procedures, not by any containing compound procedures. In this code block:
(file a, file b) A() {
a = A1();
b = A2();
}
file x, y, s, t;
(x,y) = A();
s = S(x);
t = S(y);
then a valid execution order is: A1 S(x) A2 S(y). The compound procedure A does not have to have fully completed for its return values to be used by subsequent statements.
3.6. More about types
Each variable and procedure parameter in Swift script is strongly typed. Types are used to structure data, to aid in debugging and checking program correctness and to influence how Swift interacts with data.
The image type declared in previous examples is a marker type. Marker types indicate that data for a variable is stored in a single file with no further structure exposed at the Swift script level.
Arrays have been mentioned above, in the arrays section. A code block may be applied to each element of an array using foreach; or individual elements may be references using [] notation.
There are a number of primitive types:
| type | contains |
|---|---|
int |
integers |
string |
strings of text |
float |
floating point numbers, that behave the same as Java doubles |
boolean |
true/false |
Complex types may be defined using the type keyword:
type headerfile;
type voxelfile;
type volume {
headerfile h;
voxelfile v;
}
Members of a complex type can be accessed using the . operator:
volume brain; o = p(brain.h);
Sometimes data may be stored in a form that does not fit with Swift’s file-and-site model; for example, data might be stored in an RDBMS on some database server. In that case, a variable can be declared to have external type. This indicates that Swift should use the variable to determine execution dependency, but should not attempt other data management; for example, it will not perform any form of data stage-in or stage-out it will not manage local data caches on sites; and it will not enforce component program atomicity on data output. This can add substantial responsibility to component programs, in exchange for allowing arbitrary data storage and access methods to be plugged in to scripts.
type file;
app (external o) populateDatabase() {
populationProgram;
}
app (file o) analyseDatabase(external i) {
analysisProgram @o;
}
external database;
file result <"results.txt">;
database = populateDatabase();
result = analyseDatabase(database);
Some external database is represented by the database variable. The populateDatabase procedure populates the database with some data, and the analyseDatabase procedure performs some subsequent analysis on that database. The declaration of database contains no mapping; and the procedures which use database do not reference them in any way; the description of database is entirely outside of the script. The single assignment and execution ordering rules will still apply though; populateDatabase will always be run before analyseDatabase.
3.7. Data model
Data processed by Swift is strongly typed. It may be take the form of values in memory or as out-of-core files on disk. Language constructs called mappers specify how each piece of data is stored.
3.8. More technical details about Swift script
The syntax of Swift script has a superficial resemblance to C and Java. For example, { and } characters are used to enclose blocks of statements.
A Swift script consists of a number of statements. Statements may declare types, procedures and variables, assign values to variables, and express operations over arrays.
3.9. Variables
Variables in Swift scripts are declared to be of a specific type. Assignments to those variables must be data of that type. Swift script variables are single-assignment - a value may be assigned to a variable at most once. This assignment can happen at declaration time or later on in execution. When an attempt to read from a variable that has not yet been assigned is made, the code performing the read is suspended until that variable has been written to. This forms the basis for Swift’s ability to parallelise execution - all code will execute in parallel unless there are variables shared between the code that cause sequencing.
3.10. Variable Declarations
Variable declaration statements declare new variables. They can optionally assign a value to them or map those variables to on-disk files.
Declaration statements have the general form:
typename variablename (<mapping> | = initialValue ) ;
The format of the mapping expression is defined in the Mappers section. initialValue may be either an expression or a procedure call that returns a single value.
Variables can also be declared in a multivalued-procedure statement, described in another section.
3.11. Assignment Statements
Assignment statements assign values to previously declared variables. Assignments may only be made to variables that have not already been assigned. Assignment statements have the general form:
variable = value;
where value can be either an expression or a procedure call that returns a single value.
Variables can also be assigned in a multivalued-procedure statement, described in another section.
3.12. Procedures
There are two kinds of procedure: An atomic procedure, which describes how an external program can be executed; and compound procedures which consist of a sequence of Swift script statements.
A procedure declaration defines the name of a procedure and its input and output parameters. Swift script procedures can take multiple inputs and produce multiple outputs. Inputs are specified to the right of the function name, and outputs are specified to the left. For example:
(type3 out1, type4 out2) myproc (type1 in1, type2 in2)
The above example declares a procedure called myproc, which has two inputs in1 (of type type1) and in2 (of type type2) and two outputs out1 (of type type3) and out2 (of type type4).
A procedure input parameter can be an optional parameter in which case it must be declared with a default value. When calling a procedure, both positional parameter and named parameter passings can be passed, provided that all optional parameters are declared after the required parameters and any optional parameter is bound using keyword parameter passing. For example, if myproc1 is defined as:
(binaryfile bf) myproc1 (int i, string s="foo")
Then that procedure can be called like this, omitting the optional
parameter s: binaryfile mybf = myproc1(1);
or like this supplying a value for the optional parameter s:
binaryfile mybf = myproc1 (1, s="bar");
3.12.1. Atomic procedures
An atomic procedure specifies how to invoke an external executable program, and how logical data types are mapped to command line arguments.
Atomic procedures are defined with the app keyword:
app (binaryfile bf) myproc (int i, string s="foo") {
myapp i s @filename(bf);
}
which specifies that myproc invokes an executable called myapp, passing the values of i, s and the filename of bf as command line arguments.
3.12.2. Compound procedures
A compound procedure contains a set of Swift script statements:
(type2 b) foo_bar (type1 a) {
type3 c;
c = foo(a); // c holds the result of foo
b = bar(c); // c is an input to bar
}
3.13. Control Constructs
Swift script provides if, switch, foreach, and iterate constructs, with syntax and semantics similar to comparable constructs in other high-level languages.
3.13.1. foreach
The foreach construct is used to apply a block of statements to each element in an array. For example:
check_order (file a[]) {
foreach f in a {
compute(f);
}
}
foreach statements have the general form:
foreach controlvariable (,index) in expression {
statements
}
The block of statements is evaluated once for each element in expression which must be an array, with controlvariable set to the corresponding element and index (if specified) set to the integer position in the array that is being iterated over.
3.13.2. if
The if statement allows one of two blocks of statements to be executed, based on a boolean predicate. if statements generally have the form:
if(predicate) {
statements
} else {
statements
}
where predicate is a boolean expression.
3.13.3. switch
switch expressions allow one of a selection of blocks to be chosen based on the value of a numerical control expression. switch statements take the general form:
switch(controlExpression) {
case n1:
statements2
case n2:
statements2
[...]
default:
statements
}
The control expression is evaluated, the resulting numerical value used to select a corresponding case, and the statements belonging to that case block are evaluated. If no case corresponds, then the statements belonging to the default block are evaluated.
Unlike C or Java switch statements, execution does not fall through to subsequent case blocks, and no break statement is necessary at the end of each block.
Following is an example of a switch expression in Swift:
int score=60;
switch (score){
case 100:
tracef("%s\n", "Bravo!");
case 90:
tracef("%s\n", "very good");
case 80:
tracef("%s\n", "good");
case 70:
tracef("%s\n", "fair");
default:
tracef("%s\n", "unknown grade");
}
3.13.4. iterate
iterate expressions allow a block of code to be evaluated repeatedly, with an iteration variable being incremented after each iteration.
The general form is:
iterate var {
statements;
} until (terminationExpression);
Here var is the iteration variable. Its initial value is 0. After each iteration, but before terminationExpression is evaluated, the iteration variable is incremented. This means that if the termination expression is a function of only the iteration variable, the body will never be executed while the termination expression is true.
Example:
iterate i {
trace(i); // will print 0, 1, and 2
} until (i == 3);
Variables declared inside the body of iterate can be used in the termination expression. However, their values will reflect the values calculated as part of the last invocation of the body, and may not reflect the incremented value of the iteration variable:
iterate i {
trace(i);
int j = i; // will print 0, 1, 2, and 3
} until (j == 3);
3.14. Operators
The following infix operators are available for use in Swift script expressions.
| operator | purpose |
|---|---|
+ |
numeric addition; string concatenation |
- |
numeric subtraction |
* |
numeric multiplication |
/ |
floating point division |
%/ |
integer division |
%% |
integer remainder of division |
== != |
comparison and not-equal-to |
< > ⇐ >= |
numerical ordering |
&& || |
boolean and, or |
! |
boolean not |
3.15. Global constants
At the top level of a Swift script program, the global modified may be added to a declaration so that it is visible throughout the program, rather than only at the top level of the program. This allows global constants (of any type) to be defined.
3.16. Imports
The import directive can be used to import definitions from another Swift file.
For example, a Swift script might contain this:
import "defs"; file f;
which would import the content of defs.swift:
type file;
Imported files are read from two places. They are either read from the path that is specified from the import command, such as:
import "definitions/file/defs";
or they are read from the environment variable SWIFT_LIB. This environment variable is used just like the PATH environment variable. For example, if the command below was issued to the bash shell:
export SWIFT_LIB=${HOME}/Swift/defs:${HOME}/Swift/functions
then the import command will check for the file defs.swift in both "${HOME}/Swift/defs" and "${HOME}/Swift/functions" first before trying the path that was specified in the import command.
Other valid imports:
import "../functions/func" import "/home/user/Swift/definitions/defs"
There is no requirement that a module is imported only once. If a module is imported multiple times, for example in different files, then Swift will only process the imports once.
Imports may contain anything that is valid in a Swift script, including the code that causes remote execution.
3.17. Mappers
Mappers provide a mechanism to specify the layout of mapped datasets on disk. This is needed when Swift must access files to transfer them to remote sites for execution or to pass to applications.
Swift provides a number of mappers that are useful in common cases. This section details those mappers. For more complex cases, it is possible to write application-specific mappers in Java and use them within a Swift script.
3.17.1. The Single File Mapper
The single_file_mapper maps a single physical file to a dataset.
| Swift variable | Filename |
|---|---|
f |
myfile |
f [0] |
INVALID |
f.bar |
INVALID |
| parameter | meaning |
|---|---|
file |
The location of the physical file including path and file name. |
Example:
file f <single_file_mapper;file="plot_outfile_param">;
There is a simplified syntax for this mapper:
file f <"plot_outfile_param">;
3.17.2. The Simple Mapper
The simple_mapper maps a file or a list of files into an array by prefix, suffix, and pattern. If more than one file is matched, each of the file names will be mapped as a subelement of the dataset.
| Parameter | Meaning |
|---|---|
location |
A directory that the files are located. |
prefix |
The prefix of the files |
suffix |
The suffix of the files, for instance: ".txt" |
padding |
The number of digits used to uniquely identify the mapped file. This is an optional parameter which defaults to 4. |
pattern |
A UNIX glob style pattern, for instance: "*foo*" would match all file names that contain foo. When this mapper is used to specify output filenames, pattern is ignored. |
type file; file f <simple_mapper;prefix="foo", suffix=".txt">;
The above maps all filenames that start with foo and have an extension .txt into file f.
| Swift variable | Filename |
|---|---|
f |
foo.txt |
type messagefile;
(messagefile t) greeting(string m) {.
app {
echo m stdout=@filename(t);
}
}
messagefile outfile <simple_mapper;prefix="foo",suffix=".txt">;
outfile = greeting("hi");
This will output the string hi to the file foo.txt.
The simple_mapper can be used to map arrays. It will map the array index into the filename between the prefix and suffix.
type messagefile;
(messagefile t) greeting(string m) {
app {
echo m stdout=@filename(t);
}
}
messagefile outfile[] <simple_mapper;prefix="baz",suffix=".txt", padding=2>;
outfile[0] = greeting("hello");
outfile[1] = greeting("middle");
outfile[2] = greeting("goodbye");
| Swift variable | Filename |
|---|---|
outfile[0] |
baz00.txt |
outfile[1] |
baz01.txt |
outfile[2] |
baz02.txt |
simple_mapper can be used to map structures. It will map the name of the structure member into the filename, between the prefix and the suffix.
type messagefile;
type mystruct {
messagefile left;
messagefile right;
};
(messagefile t) greeting(string m) {
app {
echo m stdout=@filename(t);
}
}
mystruct out <simple_mapper;prefix="qux",suffix=".txt">;
out.left = greeting("hello");
out.right = greeting("goodbye");
This will output the string "hello" into the file qux.left.txt and the string "goodbye" into the file qux.right.txt.
| Swift variable | Filename |
|---|---|
out.left |
quxleft.txt |
out.right |
quxright.txt |
3.17.3. Concurrent Mapper
The concurrent_mapper is almost the same as the simple mapper, except that it is used to map an output file, and the filename generated will contain an extract sequence that is unique. This mapper is the default mapper for variables when no mapper is specified.
| Parameter | Meaning |
|---|---|
location |
A directory that the files are located. |
prefix |
The prefix of the files |
suffix |
The suffix of the files, for instance: ".txt" pattern A UNIX glob style pattern, for instance: "*foo*" would match all file names that contain foo. When this mapper is used to specify output filenames, pattern is ignored. |
Example:
file f1; file f2 <concurrent_mapper;prefix="foo", suffix=".txt">;
The above example would use concurrent mapper for f1 and f2, and generate f2 filename with prefix "foo" and extension ".txt"
3.17.4. Filesystem Mapper
The filesys_mapper is similar to the simple mapper, but maps a file or a list of files to an array. Each of the filename is mapped as an element in the array. The order of files in the resulting array is not defined.
TODO: note on difference between location as a relative vs absolute path w.r.t. staging to remote location - as mihael said: It’s because you specify that location in the mapper. Try location="." instead of location="/sandbox/…"
| parameter | meaning |
|---|---|
location |
The directory where the files are located. |
prefix |
The prefix of the files |
suffix |
The suffix of the files, for instance: ".txt" |
pattern |
A UNIX glob style pattern, for instance: "*foo*" would match all file names that contain foo. |
Example:
file texts[] <filesys_mapper;prefix="foo", suffix=".txt">;
The above example would map all filenames that start with "foo" and have an extension ".txt" into the array texts. For example, if the specified directory contains files: foo1.txt, footest.txt, foo__1.txt, then the mapping might be:
| Swift variable | Filename |
|---|---|
texts[0] |
footest.txt |
texts[1] |
foo1.txt |
texts[2] |
foo__1.txt |
3.17.5. Fixed Array Mapper
The fixed_array_mapper maps from a string that contains a list of filenames into a file array.
| parameter | Meaning |
|---|---|
files |
A string that contains a list of filenames, separated by space, comma or colon |
Example:
file texts[] <fixed_array_mapper;files="file1.txt, fileB.txt, file3.txt">;
would cause a mapping like this:
| Swift variable | Filename |
|---|---|
texts[0] |
file1.txt |
texts[1] |
fileB.txt |
texts[2] |
file3.txt |
3.17.6. Array Mapper
The array_mapper maps from an array of strings into a file
| parameter | meaning |
|---|---|
files |
An array of strings containing one filename per element |
Example:
string s[] = [ "a.txt", "b.txt", "c.txt" ]; file f[] <array_mapper;files=s>;
This will establish the mapping:
| Swift variable | Filename |
|---|---|
f[0] |
a.txt |
f[1] |
b.txt |
f[2] |
c.txt |
3.17.7. Regular Expression Mapper
The regexp_mapper transforms one file name to another using regular expression matching.
| parameter | meaning |
|---|---|
source |
The source file name |
match |
Regular expression pattern to match, use |
() |
to match whatever regular expression is inside the parentheses, and indicate the start and end of a group; the contents of a group can be retrieved with the |
\\number |
special sequence (two backslashes are needed because the backslash is an escape sequence introducer) |
transform |
The pattern of the file name to transform to, use \number to reference the group matched. |
Example:
file s <"picture.gif">; file f <regexp_mapper; source=s, match="(.*)gif", transform="\\1jpg">;
This example transforms a file ending gif into one ending jpg and maps that to a file.
| Swift variable | Filename |
|---|---|
f |
picture.jpg |
3.17.8. Structured Regular Expression Mapper
The structured_regexp_mapper is similar to the regexp_mapper with the only difference that it can be applied to arrays while the regexp_mapper cannot.
| parameter | meaning |
|---|---|
source |
The source file name |
match |
Regular expression pattern to match, use |
() |
to match whatever regular expression is inside the parentheses, and indicate the start and end of a group; the contents of a group can be retrieved with the |
\\number |
special sequence (two backslashes are needed because the backslash is an escape sequence introducer) |
transform |
The pattern of the file name to transform to, use \number to reference the group matched. |
Example:
file s[] <filesys_mapper; pattern="*.gif">;
file f[] <structured_regexp_mapper; source=s,
match="(.*)gif", transform="\\1jpg">;
This example transforms all files in a list that end in gif to end in jpg and maps the list to those files.
3.17.9. CSV Mapper
The csv_mapper maps the content of a CSV (comma-separated value) file into an array of structures. The dataset type needs to be correctly defined to conform to the column names in the file. For instance, if the file contains columns: name age GPA then the type needs to have member elements like this:
type student {
file name;
file age;
file GPA;
}
If the file does not contain a header with column info, then the column names are assumed as column1, column2, etc.
| Parameter | Meaning |
|---|---|
file |
The name of the CSV file to read mappings from. |
header |
Whether the file has a line describing header info; default is |
true |
|
skip |
The number of lines to skip at the beginning (after header line); default is 0. |
hdelim |
Header field delimiter; default is the value of the |
delim |
parameter |
delim |
Content field delimiters; defaults are space, tab and comma |
Example:
student stus[] <csv_mapper;file="stu_list.txt">;
The above example would read a list of student info from file "stu_list.txt" and map them into a student array. By default, the file should contain a header line specifying the names of the columns. If stu_list.txt contains the following:
name,age,gpa 101-name.txt, 101-age.txt, 101-gpa.txt name55.txt, age55.txt, age55.txt q, r, s
then some of the mappings produced by this example would be:
| stus[0].name | 101-name.txt |
|---|---|
stus[0].age |
101-age.txt |
stus[0].gpa |
101-gpa.txt |
stus[1].name |
name55.txt |
stus[1].age |
age55.txt |
stus[1].gpa |
gpa55.txt |
stus[2].name |
q |
stus[2].age |
r |
stus[2].gpa |
s |
3.17.10. External Mapper
The external mapper, ext maps based on the output of a supplied Unix executable.
parameter |
meaning |
exec |
The name of the executable (relative to the current directory, if an absolute path is not specified) |
* |
Other parameters are passed to the executable prefixed with a - symbol |
The output (stdout) of the executable should consist of two columns of data, separated by a space. The first column should be the path of the mapped variable, in Swift script syntax (for example [2] means the 2nd element of an array) or the symbol $ to represent the root of the mapped variable. The following table shows the symbols that should appear in the first column corresponding to the mapping of different types of swift constructs such as scalars, arrays and structs.
Swift construct |
first column |
second column |
scalar |
$ |
file_name |
anarray[] |
[] |
file_name |
2dimarray[][] |
[][] |
file_name |
astruct.fld |
fld |
file_name |
astructarray[].fldname |
[].fldname |
file_name |
Example: With the following in mapper.sh,
#!/bin/bash echo "[2] qux" echo "[0] foo" echo "[1] bar"
then a mapping statement:
student stus[] <ext;exec="mapper.sh">;
would map
| Swift variable | Filename |
|---|---|
stus[0] |
foo |
stus[1] |
bar |
stus[2] |
qux |
Advanced Example: The following mapper.sh is an advanced example of an external mapper that maps a two-dimensional array to a directory of files. The files in the said directory are identified by their names appended by a number between 000 and 099. The first index of the array maps to the first part of the filename while the second index of the array maps to the second part of the filename.
#!/bin/sh
#take care of the mapper args
while [ $# -gt 0 ]; do
case $1 in
-location) location=$2;;
-padding) padding=$2;;
-prefix) prefix=$2;;
-suffix) suffix=$2;;
-mod_index) mod_index=$2;;
-outer_index) outer_index=$2;;
*) echo "$0: bad mapper args" 1>&2
exit 1;;
esac
shift 2
done
for i in `seq 0 ${outer_index}`
do
for j in `seq -w 000 ${mod_index}`
do
fj=`echo ${j} | awk '{print $1 +0}'` #format j by removing leading zeros
echo "["${i}"]["${fj}"]" ${location}"/"${prefix}${j}${suffix}
done
done
The mapper definition is as follows:
file_dat dat_files[][] < ext;
exec="mapper.sh",
padding=3,
location="output",
prefix=@strcat( str_root, "_" ),
suffix=".dat",
outer_index=pid,
mod_index=n >;
Assuming there are 4 files with name aaa, bbb, ccc, ddd and a mod_index of 10, we will have 4x10=40 files mapped to a two-dimensional array in the following pattern:
| Swift variable | Filename |
|---|---|
stus[0][0] |
output/aaa_000.dat |
stus[0][1] |
output/aaa_001.dat |
stus[0][2] |
output/aaa_002.dat |
stus[0][3] |
output/aaa_003.dat |
… |
… |
stus[0][9] |
output/aaa_009.dat |
stus[1][0] |
output/bbb_000.dat |
stus[1][1] |
output/bbb_001.dat |
… |
… |
stus[3][9] |
output/ddd_009.dat |
3.18. Executing app procedures
This section describes how Swift executes app procedures, and requirements on the behaviour of application programs used in app procedures. These requirements are primarily to ensure that the Swift can run your application in different places and with the various fault tolerance mechanisms in place.
3.18.1. Mapping of app semantics into unix process execution semantics
This section describes how an app procedure invocation is translated into a (remote) unix process execution. It does not describe the mechanisms by which Swift performs that translation; that is described in the next section.
In this section, this example Swift script is used for reference:
type file;
app (file o) count(file i) {
wc @i stdout=@o;
}
file q <"input.txt">;
file r <"output.txt">;
The executable for wc will be looked up in tc.data.
This unix executable will then be executed in some application procedure workspace. This means:
Each application procedure workspace will have an application workspace directory. (TODO: can collapse terms application procedure workspace and application workspace directory ?
This application workspace directory will not be shared with any other application procedure execution attempt; all application procedure execution attempts will run with distinct application procedure workspaces. (for the avoidance of doubt: If a Swift script procedure invocation is subject to multiple application procedure execution attempts (due to Swift-level restarts, retries or replication) then each of those application procedure execution attempts will be made in a different application procedure workspace. )
The application workspace directory will be a directory on a POSIX filesystem accessible throughout the application execution by the application executable.
Before the application executable is executed:
-
The application workspace directory will exist.
-
The input files will exist inside the application workspace directory (but not necessarily as direct children; there may be subdirectories within the application workspace directory).
-
The input files will be those files mapped to input parameters of the application procedure invocation. (In the example, this means that the file input.txt will exist in the application workspace directory)
-
For each input file dataset, it will be the case that @filename or @filenames invoked with that dataset as a parameter will return the path relative to the application workspace directory for the file(s) that are associated with that dataset. (In the example, that means that @i will evaluate to the path input.txt)
-
For each file-bound parameter of the Swift procedure invocation, the associated files (determined by data type?) will always exist.
-
The input files must be treated as read only files. This may or may not be enforced by unix file system permissions. They may or may not be copies of the source file (conversely, they may be links to the actual source file).
During/after the application executable execution, the following must be true:
-
If the application executable execution was successful (in the opinion of the application executable), then the application executable should exit with unix return code 0; if the application executable execution was unsuccessful (in the opinion of the application executable), then the application executable should exit with unix return code not equal to 0.
-
Each file mapped from an output parameter of the Swift script procedure call must exist. Files will be mapped in the same way as for input files.
-
The output subdirectories will be precreated before execution by Swift if defined within a Swift script such as the location attribute of a mapper. App executables expect to make them if they are referred to in the wrapper scripts.
-
Output produced by running the application executable on some inputs should be the same no matter how many times, when or where that application executable is run. The same can vary depending on application (for example, in an application it might be acceptable for a PNG→JPEG conversion to produce different, similar looking, output jpegs depending on the environment)
Things to not assume:
-
Anything about the path of the application workspace directory
-
That either the application workspace directory will be deleted or will continue to exist or will remain unmodified after execution has finished
-
That files can be passed between application procedure invocations through any mechanism except through files known to Swift through the mapping mechanism (there is some exception here for external datasets - there are a separate set of assertions that hold for external datasets)
-
That application executables will run on any particular site of those available, or than any combination of applications will run on the same or different sites.
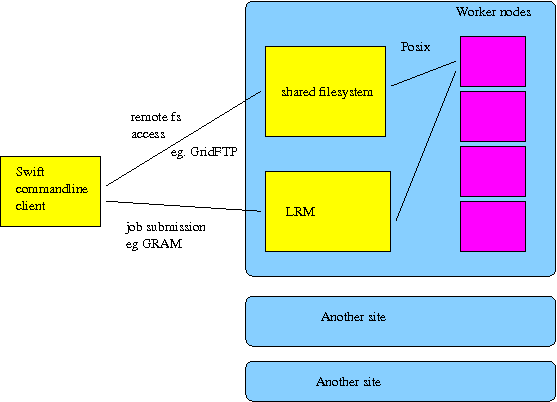
3.19. How Swift implements the site execution model
This section describes the implementation of the semantics described in the previous section.
Swift executes application procedures on one or more sites.
Each site consists of:
-
worker nodes. There is some execution mechanism through which the Swift client side executable can execute its wrapper script on those worker nodes. This is commonly GRAM or Falkon or coasters.
-
a site-shared file system. This site shared filesystem is accessible through some file transfer mechanism from the Swift client side executable. This is commonly GridFTP or coasters. This site shared filesystem is also accessible through the posix file system on all worker nodes, mounted at the same location as seen through the file transfer mechanism. Swift is configured with the location of some site working directory on that site-shared file system.
There is no assumption that the site shared file system for one site is accessible from another site.
For each workflow run, on each site that is used by that run, a run directory is created in the site working directory, by the Swift client side.
In that run directory are placed several subdirectories:
-
shared/ - site shared files cache
-
kickstart/ - when kickstart is used, kickstart record files for each job that has generated a kickstart record.
-
info/ - wrapper script log files
-
status/ - job status files
-
jobs/ - application workspace directories (optionally placed here - see below)
Application execution looks like this:
For each application procedure call:
The Swift client side selects a site; copies the input files for that procedure call to the site shared file cache if they are not already in the cache, using the file transfer mechanism; and then invokes the wrapper script on that site using the execution mechanism.
The wrapper script creates the application workspace directory; places the input files for that job into the application workspace directory using either cp or ln -s (depending on a configuration option); executes the application unix executable; copies output files from the application workspace directory to the site shared directory using cp; creates a status file under the status/ directory; and exits, returning control to the Swift client side. Logs created during the execution of the wrapper script are stored under the info/ directory.
The Swift client side then checks for the presence of and deletes a status file indicating success; and copies files from the site shared directory to the appropriate client side location.
The job directory is created (in the default mode) under the jobs/ directory. However, it can be created under an arbitrary other path, which allows it to be created on a different file system (such as a worker node local file system in the case that the worker node has a local file system).
3.20. Technical overview of the Swift architecture
This section attempts to provide a technical overview of the Swift architecture.
3.20.1. Execution layer
The execution layer causes an application program (in the form of a unix executable) to be executed either locally or remotely.
The two main choices are local unix execution and execution through GRAM. Other options are available, and user provided code can also be plugged in.
The kickstart utility can be used to capture environmental information at execution time to aid in debugging and provenance capture.
3.20.2. Swift script language compilation layer
Step i: text to XML intermediate form parser/processor. parser written in ANTLR - see resources/VDL.g. The XML Schema Definition (XSD) for the intermediate language is in resources/XDTM.xsd.
Step ii: XML intermediate form to Karajan workflow. Karajan.java - reads the XML intermediate form. compiles to karajan workflow language - for example, expressions are converted from Swift script syntax into Karajan syntax, and function invocations become karajan function invocations with various modifications to parameters to accomodate return parameters and dataset handling.
3.20.3. Swift/karajan library layer
Some Swift functionality is provided in the form of Karajan libraries that are used at runtime by the Karajan workflows that the Swift compiler generates.
3.21. Function reference
This section details functions that are available for use in the Swift language.
3.21.1. arg
Takes a command line parameter name as a string parameter and an optional default value and returns the value of that string parameter from the command line. If no default value is specified and the command line parameter is missing, an error is generated. If a default value is specified and the command line parameter is missing, @arg will return the default value.
Command line parameters recognized by @arg begin with exactly one hyphen and need to be positioned after the script name.
For example:
trace(arg("myparam"));
trace(arg("optionalparam", "defaultvalue"));
$ swift arg.swift -myparam=hello Swift v0.3-dev r1674 (modified locally) RunID: 20080220-1548-ylc4pmda Swift trace: defaultvalue Swift trace: hello
3.21.2. extractInt
extractInt(file) will read the specified file, parse an integer from the file contents and return that integer.
3.21.3. extractFloat
Similar to extractInt, extractFloat(file) will read the specified file, parse a float from the file contents and return that float.
3.21.4. filename
filename(v) will return a string containing the filename(s) for the file(s) mapped to the variable v. When more than one filename is returned, the filenames will be space separated inside a single string return value.
3.21.5. filenames
filenames(v) will return multiple values containing the filename(s) for the file(s) mapped to the variable v.
3.21.6. length
length(array) will return the length of an array in Swift. This function will wait for all elements in the array to be written before returning the length.
3.21.7. readData
readData will read data from a specified file and assign it to Swift variable. The format of the input file is controlled by the type of the return value. For scalar return types, such as int, the specified file should contain a single value of that type. For arrays of scalars, the specified file should contain one value per line. For complex types of scalars, the file should contain two rows. The first row should be structure member names separated by whitespace. The second row should be the corresponding values for each structure member, separated by whitespace, in the same order as the header row. For arrays of structs, the file should contain a heading row listing structure member names separated by whitespace. There should be one row for each element of the array, with structure member elements listed in the same order as the header row and separated by whitespace. The following example shows how readData() can be used to populate an array of Swift struct-like complex type:
type Employee{
string name;
int id;
string loc;
}
Employee emps[] = readData("emps.txt");
Where the contents of the "emps.txt" file are:
name id loc Thomas 2222 Chicago Gina 3333 Boston Anne 4444 Houston
This will result in the array "emps" with 3 members. This can be processed within a Swift script using the foreach construct as follows:
foreach emp in emps{
tracef("Employee %s lives in %s and has id %d", emp.name, emp.loc, emp.id);
}
3.21.8. readStructured
readStructured will read data from a specified file, like readdata, but using a different file format more closely related to that used by the ext mapper.
Input files should list, one per line, a path into a Swift structure, and the value for that position in the structure:
rows[0].columns[0] = 0 rows[0].columns[1] = 2 rows[0].columns[2] = 4 rows[1].columns[0] = 1 rows[1].columns[1] = 3 rows[1].columns[2] = 5
which can be read into a structure defined like this:
type vector {
int columns[];
}
type matrix {
vector rows[];
}
matrix m;
m = readStructured("readStructured.in");
(since Swift 0.7, was readData2(deprecated))
3.21.9. regexp
regexp(input,pattern,replacement) will apply regular expression substitution using the Java java.util.regexp API http://java.sun.com/j2se/1.4.2/docs/api/java/util/regex/Pattern.html. For example:
string v = regexp("abcdefghi", "c(def)g","monkey");
will assign the value "abmonkeyhi" to the variable v.
3.21.10. sprintf
sprintf(spec, variable list) will generate a string based on the specified format.
Example: string s = sprintf("\t%s\n", "hello");
Format specifiers
%% |
% sign |
%M |
Filename output (waits for close) |
%p |
Format variable according to an internal format |
%b |
Boolean output |
%f |
Float output |
%i |
int output |
%s |
String output |
%k |
Variable sKipped, no output |
%q |
Array output |
3.21.11. strcat
strcat(a,b,c,d,…) will return a string containing all of the strings passed as parameters joined into a single string. There may be any number of parameters.
The + operator concatenates two strings: strcat(a,b) is the same as a + b
3.21.12. strcut
strcut(input,pattern) will match the regular expression in the pattern parameter against the supplied input string and return the section that matches the first matching parenthesised group.
For example:
string t = "my name is John and i like puppies.";
string name = strcut(t, "my name is ([^ ]*) ");
string out = strcat("Your name is ",name);
trace(out);
This will output the message: Your name is John.
3.21.13. strjoin
strjoin(array, delimiter) will combine the elements of an array into a single string separated by a given delimiter. The array passed to strjoin must be of a primitive type (string, int, float, or boolean). It will not join the contents of an array of files.
Example:
string test[] = ["this", "is", "a", "test" ];
string mystring = strjoin(test, " ");
tracef("%s\n", mystring);
This will print the string "this is a test".
3.21.14. strsplit
strsplit(input,pattern) will split the input string based on separators that match the given pattern and return a string array.
Example:
string t = "my name is John and i like puppies.";
string words[] = strsplit(t, "\\s");
foreach word in words {
trace(word);
}
This will output one word of the sentence on each line (though not necessarily in order, due to the fact that foreach iterations execute in parallel).
3.21.15. toInt
toInt(input) will parse its input string into an integer. This can be used with arg() to pass input parameters to a Swift script as integers.
3.21.16. toFloat
toFloat(input) will parse its input string into a floating point number. This can be used with arg() to pass input parameters to a Swift script as floating point numbers.
3.21.17. toString
toString(input) will parse its input into a string. Input can be an int, float, string, or boolean.
3.21.18. trace
trace will log its parameters. By default these will appear on both stdout and in the run log file. Some formatting occurs to produce the log message. The particular output format should not be relied upon.
3.21.19. tracef
tracef(spec, variable list) will log its parameters as formatted by the formatter spec. spec must be a string. Checks the type of the specifiers arguments against the variable list and allows for certain escape characters.
Example:
int i = 3;
tracef("%s: %i\n", "the value is", i);
Specifiers:
- %s
-
Format a string.
- %b
-
Format a boolean.
- %i
-
Format a number as an integer.
- %f
-
Format a number as a floating point number.
- %q
-
Format an array.
- %M
-
Format a mapped variable’s filename.
- %k
-
Wait for the given variable but do not format it.
- %p
-
Format variable according to an internal format.
Escape sequences:
- \n
-
Produce a newline.
- \t
-
Produce a tab.
- Known issues:
-
Swift does not correctly scan certain backslash sequences such as \\.
3.21.20. java
java(class_name, static_method, method_arg) will call a java static method of the class class_name.
3.21.21. writeData
writeData will write out data structures in the format described for readData. The following example demonstrates how one can write a string "foo" into a file "writeDataPrimitive.out":
type file; string s = "foo"; file f <"writeDataPrimitive.out">; f=writeData(s);
4. Configuration
Swift is mainly configured using a configuration file, typically called swift.conf. This file contains configuration properties and site descriptions. A simple configuration file may look like this:
site.mysite {
execution {
type: "coaster"
URL: "my.site.org"
jobManager: "ssh:local"
}
staging: "local"
app.ALL {executable: "*"}
}
# select sites to run on
sites: [mysite]
# other settings
lazy.errors: false
4.1. Configuration Syntax
The Swift configuration files are expressed in a modified version of JSON. The main additions to JSON are:
-
Quotes around string values, in particular keys, are optional, unless the strings contain special characters (single/double quotes, square and curly braces, white space, $, :, =, ,, `, ^, ?, !, @, *, \), or if they represent other values: true, false, null, and numbers.
-
= and : can be used interchangeably to separate keys from values
-
= (or :) is optional before an open bracket
-
Commas are optional as separators if there is a new line
-
${…} expansion can be used to substitute environment variable values or Java system properties. If the value of an environment variable is needed, it must be prefixed with env.. For example ${env.PATH}. Except for include directives, the ${…} must not be inside double quotes for the substitution to work. The same outcome can be achieved using implicit string concatenation: "/home/"${env.USER}"/bin"
Comments can be introduced by starting a line with a hash symbol (#) or using a double slash (//):
# This is a comment // This is also a comment keepSitesDir: true # This is a comment following a valid property
4.2. Include Directives
Include directives can be used to include the contents of a Swift configuration file from another Swift configuration file. This is done using the literal include followed by a quoted string containing the path to the target file. The path may contain references to environment variables or system properties using the substitution syntax explained above. For example:
# an absolute path name
include "/home/joedoe/swift-config/site1.conf"
# include a file from the Swift distribution package
include "${swift.home}/etc/sites/beagle.conf"
# include a file using an environment variable
include "${env.SWIFT_CONFIG_DIR}/glow.conf"
4.3. Property Merging
If two properties with the same name are present in a configuration file, they are either merged or the latter one overrides the earlier one. This depends on the type of property. Simple values are always overridden, while objects are merged. For example:
key: 1
key: 2
# key is now 2
object {
key1: 1
}
object {
key2: 2
}
# object is now { key1: 1, key2: 2}
This can be used to define certain template files that contain most of the definitions for sites, and then include them in other files and override or add only certain aspects of those sites. For example, assume swift-local.conf includes a definition for a site named local that can be used to run applications on the Swift client side. If you wanted to override only the work directory, the following swift.conf could be used:
include "swift-local.conf"
site.local {
# use existing definition for site.local, but override workDirectory
workDirectory: "/tmp"
}
If, on the other hand, you want to fully override the definition of site.local, you could set it to null first and then provide your own definition:
include "swift-local.conf"
# forget previous definition of site.local
site.local: null
# define your own site.local
site.local {
...
}
4.4. Configuration Search Path
By default, Swift attempts to load multiple configuration files, merging them sequentially as described in the Property Merging Section. The files are:
-
Distribution Configuration ([D]): ${swift.home}/etc/swift.conf
-
Site Configuration ([S]): ${env.SWIFT_SITE_CONF} (if SWIFT_SITE_CONF is defined)
-
User Configuration ([U]): ${env.HOME}/.swift/swift.conf (if present)
-
Run Configiuration ([R]): ${env.PWD}/swift.conf (if present)
In addition, a number of configuration properties can be overridden individually on the Swift command line. For a list of such configuration properties, please use swift -help or refer to the <<??, Running Swift>> Section in this document.
The run configuration can be overridden on the Swift command line using the -config argument. If -config is specified, Swift will not attempt to load swift.conf from the current directory.
The entire configuration search path can be replaced with a custom search path using the -configpath command line argument. The value passed to -configpath must be a list of paths pointing to various configuration files, separated by the standard operating system path separator (: on Linux and ; on Windows). For example:
swift -configpath /etc/swift/swift.conf:~/swift-configs/s1.conf:swift.conf
If in doubt about what configuration files are being loaded or to troubleshoot configuration issues, Swift can be started with the -listconfig command line argument. -listconfig accepts to possible values:
-
files: will print a list of configuration files loaded by Swift
-
full: will print a list of configuration files loaded by Swift, as well as the final merged configuration.
4.5. Configuration File Structure
The contents of a Swift configuration file can be divided into a number of relevant sections:
-
site declarations
-
global application declarations
-
Swift configuration properties
4.5.1. Site Declarations
Swift site declarations are specified using the site.<name> property, where text inside angle brackets is to be interpreted as a generic label for user-specified content, whereas content between square brackets is optional:
site.<name> {
execution {...}
[staging: "swift" | "local" | "service-local" | "shared-fs" | "wrapper"]
[filesystem {...}]
workDirectory: <path>
[<site options>]
[<application declarations>]
}
A site name can be any string. If the string contains special characters, it must be quoted:
site."My-$pecial-$ite" {...}
4.5.2. Site Selection
Once sites are declared, they must be explicitly enabled for Swift to use them. This can be achieved with the sites option, which accepts either an array or a comma-separated list of site names:
sites: ["site1", "site2"] # alternatively: sites: "site1, site2"
The sites option can also be specified on the Swift command line:
swift -sites site1,site2 script.swift
Execution Mechanism
The execution property tells Swift how applications should be executed on a site:
execution {
type: <string>
[URL: <string>]
[jobManager: <string>]
[<execution provider options>]
}
The type property is used to select one of the mechanisms for application execution that is known by Swift. A comprehensinve list of execution mechanisms can be found in Execution Mechanisms Section. A summary is shown below:
| Type | URL required | Uses jobManager | Default jobManager | Staging methods supported | Description |
|---|---|---|---|---|---|
local |
no |
no |
- |
swift, local, wrapper |
Runs applications locally using a simple fork()-based mechanism |
coaster |
yes |
yes |
none |
swift, wrapper, local, service-local, shared-fs, direct |
Submits applications through an automatically-deployed Swift Coasters service |
coaster-persistent |
yes |
yes |
none |
swift, wrapper, local, service-local, shared-fs, direct |
Uses a manually deployed Swift Coasters service |
GRAM5 |
yes |
yes |
"fork" |
swift, wrapper |
Uses the GRAM: User’s Guide component of the Globus Toolkit. |
GT2 |
An alias for GRAM5 |
||||
SSH |
yes |
no |
- |
swift, wrapper |
Runs applications using a Java implementation of the SSH protocol |
SSH-CL |
yes |
no |
- |
swift, wrapper |
Like SSH except it uses the command-line ssh tool. |
PBS |
no |
no |
- |
swift, wrapper |
Submits applications to a PBS or Torque resource manager |
Condor |
no |
no |
- |
swift, wrapper |
Submits applications using Condor |
SGE |
no |
no |
- |
swift, wrapper |
Uses the Sun Grid Engine |
SLURM |
no |
no |
- |
swift, wrapper |
Uses the SLURM local scheduler |
LSF |
no |
no |
- |
swift, wrapper |
Submits applications to Platform’s Load Sharing Facility |
The execution provider options are options that specify finer details on how on application should be executed. They depend on the chosen mechanism and are detailed in Execution Mechanisms Section. This is where Coasters options, such as nodeGranularity or softImage, would be specified. Example:
execution {
type: "coaster"
jobManager: "local:local"
options {
maxJobs: 1
tasksPerNode: 2
workerLoggingLevel: TRACE
}
}
A complete list of Swift Coasters options can be found in Coaster Options
Staging
The staging property instructs Swift how to handle application input and output files. The swift and wrapper staging methods are supported universally, but the swift method requires the filesystem property to be specified. If not specified, this option defaults to swift. Support for the other choices is dependent on the execution mechanism. This is detailed in the Execution Mechanisms Table above. A description of each staging method is provided in the table below:
| Staging Method | Description |
|---|---|
swift |
This method instructs Swift to use a filesystem provider to direct all necessary staging operations from the Swift client-side to the cluster head node. If this method is used, the workDirectory must point to a head node path that is on a shared file system accessible by the compute nodes. |
wrapper |
File staging is done by the Swift application wrapper |
local |
Used to indicate that files should be staged in/out from/to the site on which Swift is running. In the case of Swift Coasters, the system proxies the tranfers between client side and compute nodes through the Coaster Service. |
service-local |
This method instructs the execution mechanism provider to stage input and output files from the remote site where the execution service is located. For example, if a Coaster Service is started on the login node of a cluster, the Coaster Service will perform the staging from a file system on the login node to the compute node and back. |
shared-fs |
This method is used by Coasters to implement a simple staging mechanism in which files are accessed using a shared filesystem that is accessible by compute nodes |
direct |
Tries to avoid moving files around as much as possible and passes absolute file names to the application instead. The node on which the application is running must have access to the filesystem on which swift data is located. |
File System
The file system properties are used with staging: "swift" to tell Swift how to access remote file systems. Valid types are described below:
| Type | URL required | Description |
|---|---|---|
local |
no |
Copies files locally on the Swift client side |
GSIFTP |
yes |
Accesses a remote file system using GridFTP |
GridFTP |
yes |
An alias for GSIFTP |
SSH |
yes |
Uses the SCP protocol |
Site Options
Site options control various aspects of how Swift handles application execution on a site. All options except workDirectory are optional. They are listed in the following table:
| Option | Valid values | Default value | Description |
|---|---|---|---|
OS |
many |
"INTEL32::LINUX" |
Can be used to tell Swift the type of the operating system running on the remote site. By default, Swift assumes a UNIX/Linux type OS. There is some limited support for running under Windows, in which case this property must be set to one of "INTEL32::WINDOWS" or "INTEL64::WINDOWS" |
workDirectory |
path |
- |
Points to a directory in which Swift can maintain a set of files relevant to the execution of an application on the site. By default, applications will be executed on the compute nodes in a sub-directory of workDirectory, which implies that workDirectory must be accessible from the compute nodes. |
scratch |
path |
- |
If specified, it instructs swift to run applications in a directory different than workDirectory. Contrary to the requirement for workDirectory, scratch can point to a file system local to compute nodes. This option is useful if applications do intensive I/O on temporary files created in their work directory, or if they access their input/output files in a non-linear fashion. |
keepSiteDir |
true, false |
false |
If set to true, site application directories (i.e. workDirectory) will not be cleaned up when Swift completes a run. This can be useful for debugging. |
statusMode |
"files", "provider" |
"files" |
Controls whether application exit codes are handled by the execution mechanism or passed back to Swift by the Swift wrapper script through files. Traditionally, Globus GRAM did not use to return application exit codes. This has changed in Globus Toolkit 5.x. However, some local scheduler execution mechanisms, such as PBS, are still unable to return application exit codes. In such cases, it is necessary to pass the application exit codes back to Swift in files. This comes at a slight price in performance, since a file needs to be created, written to, and transferred back to Swift for each application invocation. It is however also the default, since it works in all cases. |
maxParallelTasks |
integer |
2 |
The maximum number of concurrent application invocations allowed on this site. |
initialParallelTasks |
integer |
2 |
The limit on the number of concurrent application invocations on this site when a Swift run is started. As invocations complete successfully, the number of concurrent invocations on the site is increased up to maxParallelTasks. |
Additional, less frequently used options, are as follows:
| Option | Valid values | Default value | Description |
|---|---|---|---|
wrapperParameterMode |
"args", "files" |
"args" |
If set to "files", Swift will, as much as possible, pass application arguments through files. The applications will be invoked normally, with their arguments in the **argv parameter to the main() function. This can be useful if the execution mechanism has limitations on the size of command line arguments that can be passed through. An example of execution mechanism exhibiting this problem is Condor. |
wrapperInterpreter |
path |
"/bin/bash" or "cscript.exe" on Windows |
Points to the interpreter used to run the Swift application invocation wrapper |
wrapperScript |
string |
"_swiftwrap" or "_swiftwrap.vbs" on Windows |
Points to the Swift application invocation wrapper. The file must exist in the libexec directory in the Swift distribution |
wrapperInterpreterOptions |
list of strings |
[] on UNIX/Linux or ["//Nologo"] on Windows |
Command line options to be passed to the wrapper interpreter |
cleanupCommand |
string |
"/bin/rm" or "cmd.exe" on Windows |
A command to use for the cleaning of site directories (unless keepSiteDir is set to true) at the end of a run. |
cleanupCommandOptions |
list of strings |
["-rf"] or ["/C", "del", "/Q"] on Windows |
Arguments to pass to the cleanup command when cleaning up site work directories |
delayBase |
number |
2.0 |
Swift keeps a quality indicator for each site it runs applications on. This is a number that gets increased for every successful application invocation, and decreased for every failure. It then uses this number in deciding which sites to run applications on (when multiple sites are defined). If this number becomes very low (a sign of repeated failures on a site), Swift implements an exponential back-off that prevents jobs from being sent to a site that continously fails them. delayBase is the base for that exponential back-off: delay = delayBase ^ (-score * 100) |
maxSubmitRate |
positive number |
- |
Some combinations of site and execution mechanisms may become error prone if jobs are submitted too fast. This option can be used to limit the submission rate. If set to some number N, Swift will submit applications at a rate of at most N per second. |
Application Declarations
Applications can either be declared globally, outside of a site declaration, or specific to a site, inside a site declaration:
app.(<appName>|ALL) {
# global application
...
}
site.<siteName> {
app.(<appName>|ALL) {
# site application
...
}
}
A special application name, ALL, can be used to declare options for all applications. When Swift attempts to run an application named X, it will first look at site application declarations for app.X. If not found, it will check if a site application declaration exists for app.ALL. The search will continue with the global app.X and then the global all.ALL until a match is found. It is possible that a specific application will only be declared on a sub-set of all the sites and not globally. Swift will then only select a site where the application is declared and will not attempt to run the application on other sites.
An application declaration takes the following form:
app.<appName> {
executable: (<string>|"*")
[jobQueue: <string>]
[jobProject: <string>]
[maxWallTime: <time>]
[options: {...}]
<environment variables>
}
The executable is mandatory, and it points to the actual location of the executable that implements the application. The special string "*" can be used to indicate that the executable has the same name as the application name. This is useful in conjunction with app.ALL to essentially declare that a site can be used to execute any application from a Swift script. If the executable is not an absolute path, it will be searched using the PATH envirnoment variable on the remote site.
Environment variables can be defined as follows:
env.<name>: <value>
For example:
env.LD_LIBRARY_PATH: "/home/joedoe/lib"
The remaining options are:
| Name | Valid values | Description |
|---|---|---|
jobQueue |
any |
If the application is executed using a mechanism that submits to a queuing system, this option can be used to select a specific queue for the application |
jobProject |
any |
A queuing system project to associate the job with. |
maxWallTime |
"mm" or "hh:mm" or "hh:mm:ss" |
The maximum amount of time that the application will take to execute on the site. Most application execution mechanisms will both require and enforce this value by terminating the application if it exceeds the specified time. The default value is 10 minutes. |
General Swift Options
There are a number of configuration options that modify the way that the Swift run-time behaves. They are listed below:
| Name | Valid values | Default value | Description |
|---|---|---|---|
sites |
array of strings (e.g. ["site1", "site2"]) or CSV string (e.g. "site1, site2") |
none |
Selects, out of the set of all declared sites, a sub-set of sites to run applications on. |
hostName |
string |
autodetected |
Can be used to specify a publicly reacheable DNS name or IP address for this machine which is generally used for Globus or Coaster callbacks. Normally this should be auto-detected, but if you do not have a public DNS name, you may want to set this. |
TCPPortRange |
"lowPort, highPort" |
none |
A TCP port range can be specified to restrict the ports on which certain callback services are started. This is likely needed if your submit host is behind a firewall, in which case the firewall should be configured to allow incoming connections on ports in this range. |
lazyErrors |
true, false |
false |
Use a lazy mode to deal with errors. When set to true Swift will proceed with the execution until no more data can be derived because of errors in dependent steps. If set to false, an error will cause the execution to immediately stop |
executionRetries |
non-negative integer |
0 |
The number of time an application invocation will be retries if it fails until Swift
finally gives up and declares it failed. The total number of attempts will be 1 |
logProvenance |
true, false |
false |
If set to true, Swift will record provenance information in the log file. |
alwaysTransferWrapperLog |
true, false |
false |
Controls when wrapper logs are transfered back to the submit host. If set to false, Swift will only transfer a wrapper log for a given job when that job fails. If set to true, Swift will transfer wrapper logs whether a job fails or not. |
fileGCEnabled |
true, false |
true |
Controls the file garbage collector. If set to false, files mapped by collectable mappers (such as the concurrent mapper) will not be deleted when their Swift variables go out of scope. |
mappingCheckerEnabled |
true, false |
true |
Controls the run-time duplicate mapping checker (which indetifies mapping conflicts). When enabled, a record of all mapped data is kept, so this comes at the expense of a slight memory leak. If set false, the mapping checker is disabled. |
tracingEnabled |
true, false |
false |
Enables execution tracing. If set to true, operations within Swift such as iterations, invocations, assignments, and declarations, as well as data dependencies will be logged. This comes at a cost in performance. It is therefore disabled by default. |
maxForeachThreads |
positive integer |
16384 |
Limits the number of concurrent iterations that each foreach statement can have at one time. This conserves memory for swift programs that have large numbers of iterations (which would otherwise all be executed in parallel). |
Ticker |
|||
tickerEnabled |
true, false |
true |
Controls the output ticker, which regularly prints information about the counts of application states on the Swift’s process standard output |
tickerPrefix |
string |
"Progress: " |
Specifies a string to prefix to each ticker line output |
tickerDateFormat |
string |
"E, dd MMM yyyy HH:mm:ssZ" |
Specifies the date/time format to use for the time stamp of each ticker line. It must conform to Java’s <http://docs.oracle.com/javase/7/docs/api/java/text/SimpleDateFormat.html,SimpleDateFormat> syntax. |
CDM |
|||
CDMBroadcastMode |
string |
"file" |
- |
CDMLogFile |
string |
"cdm.log" |
- |
Replication |
|||
replicationEnabled |
true, false |
false |
If enabled, jobs that are queued longer than a certain amount of time will have a duplicate version re-submitted. This process will continue until a maximum pre-set number of such replicas is queued. When one of the replicas becomes active, all other replicas are canceled. This mechanism can potentially prevent a single overloaded site from completely blocking a run. |
replicationMinQueueTime |
seconds |
60 |
When replication is enabled, this is the amount of time that a job needs to be queued until a new replica is created. |
replicationLimit |
integer > 0 |
3 |
The maximum number of replicas allowed for a given application instance. |
Wrapper Staging |
|||
wrapperStagingLocalServer |
string |
"file://" |
When file staging is set to "wrapper", this indicates the default URL scheme that is prefixed to local files. |
Throttling |
|||
jobSubmitThrottle |
integer > 0 or "off" |
4 |
Limits the number of jobs that can concurrently be in the process of being submitted, that is in the "Submitting" state. This is the state where the job information is being communicated to a remote service. Certain execution mechanisms may become inefficient if too many jobs are being submitted concurrently and there are no benefits to parallelizing submission beyond a certain point. Please not that this does not apply to the number of jobs that can be active concurrently. |
hostJobSubmitThrottle |
integer > 0 or "off" |
2 |
Like jobSubmitThrottle, except it applies to each individual site. |
fileTransfersThrottle |
integer > 0 or "off" |
4 |
Limits the number of concurrent file transfers when file staging is set to "swift". Arbitrarily increasing file transfer parallelism leads to little benefits as the throughput approaches the maximum avaiable network bandwidth. Instead it can lead to an increase in latencies which may increase the chances of triggering timeouts. |
fileOperationsThrottle |
integer > 0 or "off" |
8 |
Limits the number of concurrent file operations that can be active at a given time when file staging is set to "swift". File operations are defined to be all remote operations on a filesystem that exclude file transfers. Examples are: listing the contents of a directory, creating a directory, removing a file, etc. |
Global versions of site options |
|||
staging |
"swift", "local", "service-local", "shared-fs", "wrapper" |
"swift" |
See Staging Methods. |
keepSiteDir |
true, false |
false |
See Site Options. |
statusMode |
"files", "provider" |
"files" |
See Site Options. |
wrapperParameterMode |
"args", "files" |
"args" |
See Other Site Options. |
4.6. Run directories
When you run Swift, you will see a run directory get created. The run directory has the name of runNNN, where NNN starts at 000 and increments for every run.
The run directories can be useful for debugging. They contain: .Run directory contents
apps |
An apps generated from swift.properties |
cf |
A configuration file generated from swift.properties |
runNNN.log |
The log file generated during the Swift run |
scriptname-runNNN.d |
Debug directory containing wrapper logs |
scripts |
Directory that contains scheduler scripts used for that run |
sites.xml |
A sites.xml generated from swift.properties |
swift.out |
The standard out and standard error generated by Swift |
4.7. Execution Mechanisms
Swift allows application execution through a number of mechanisms (or execution providers). The choice of each mechanism is dependent on the software installed on a certain compute cluster. The following sub-sections list the available choices together with their supported options.
4.7.1. Local
The local execution mechanism can be used to run applications locally through simple fork() calls.
General Configuration
URL required |
no |
Job Manager |
not used |
Staging methods |
swift, wrapper, local, service-local, shared-fs, direct |
Options
N/A
Job Options
| Name | Type | Default Value | Description |
|---|---|---|---|
count |
Integer |
1 |
Launch this many copies of the application for each invocation |
Example
site.local {
execution {
type: "local"
}
staging: direct
app.ALL {
executable: "*"
count: 1
}
}
4.7.2. GT5
Uses the <http://toolkit.globus.org/toolkit/docs/latest-stable/gram5/#gram5,GRAM> component of the Globus Toolkit to launch jobs on remote resources.
General Configuration
URL required |
yes |
Job Manager |
In GRAM, job managers instruct the GRAM service to submit
jobs to specific resource managers on the server side. The
exact available job managers depend on the particular GRAM
installation. However, "fork", which instructs GRAM to
run jobs directly on the service node, should always be
available. In addition, the available job managers would
typically match the queuing systems installed on the server
side. For example, if a cluster uses Torque/PBS, then the
"PBS" |
Staging methods |
swift, wrapper |
Options
N/A
Job Options
For a complete list and description of these options, please see the Globus GRAM documentation
| Name | Type | Default Value | Description |
|---|---|---|---|
count |
Integer |
1 |
Launch this many copies of the application for each invocation |
max_time |
Integer (minutes) |
- |
|
max_wall_time |
Integer (minutes) |
- |
|
max_cpu_time |
Integer (minutes) |
- |
|
max_memory |
Integer (MB) |
- |
|
min_memory |
Integer (MB) |
- |
|
project |
String |
- |
A LRM project to associate the job with |
queue |
String |
- |
LRM queue to submit to |
Example
site.example {
execution {
type: "gt5"
url: "login.example.org"
jobManager: "PBS"
}
staging: swift
app.sim {
executable: /usr/bin/sim
queue: "fast"
min_memory: 120
}
}
4.7.3. SSH
Runs jobs through a Java implementation of the SSH protocol. This mechanism generally results in a higher throughput than using the command-line SSH tool since it can reduce the number of authentication operations by re-using connections.
General Configuration
URL required |
yes |
Job Manager |
not used |
Staging methods |
swift, wrapper |
Options
N/A
Job Options
N/A
Example
site.example {
execution {
type: "ssh"
url: "login.example.org"
}
}
4.7.4. SSH-CL
Uses the ssh command-line tool to run jobs.
General Configuration
URL required |
yes |
Job Manager |
not used |
Staging methods |
swift, wrapper |
Options
N/A
Job Options
N/A
Example
site.example {
execution {
type: "ssh-cl"
url: "login.example.org"
}
}
4.7.5. PBS
Submits jobs directly to a Torque/PBS queue.
General Configuration
URL required |
no |
Job Manager |
not used |
Staging methods |
swift, wrapper |
Options
N/A
Job Options
| Name | Type | Default Value | Description |
|---|---|---|---|
count |
Integer |
1 |
Request this number of nodes for the job |
ppn |
Integer |
1 |
Sets the number of Processes Per Node |
depth |
Integer |
1 |
Only used if mpp is set to true. Sets the depth (number of OpenMP threads/cores to allocate for each process) |
pbs.mpp |
Boolean |
false |
If set to true, use the mpp versions of count, ppn, and depth: mppwidth, mppnppn, mppdepth respectively. |
pbs.properties |
String |
- |
If specified, this string will be passed verbatim to PBS inside the "#PBS -l" line. |
project |
String |
- |
A PBS project to associate the job with |
queue |
String |
- |
PBS queue to submit to |
pbs.resource_list |
String |
- |
WRITEME! |
pbs.aprun |
Boolean |
false |
If specified, use the aprun tool instead of ssh to start jobs on the compute nodes. aprun is a tool typically found on Cray systems. |
Example
site.pbs {
execution {
type: "PBS"
}
app.sim {
executable: "/usr/bin/sim"
count: 2
ppn: 2
depth: 2
pbs.mpp: true
queue: "fast"
}
}
4.7.6. Condor
Submits jobs using the HTCondor system.
General Configuration
URL required |
no |
Job Manager |
not used |
Staging methods |
swift, wrapper |
Options
N/A
Job Options
| Name | Type | Default Value | Description |
|---|---|---|---|
jobType |
"MPI", "grid", "nonshared", none |
none |
Specifies the job type (Condor universe). "nonshared" translates to the "vanilla" universe. |
holdIsFailure |
Boolean |
false |
Treat jobs in the held state as failed. |
count |
Integer |
1 |
Number of machines to request for the job |
condor.* |
Any |
- |
Can be used to pass arbitrary properties to Condor. |
Example
site.condor {
execution {
type: "Condor"
}
app.sim {
executable: "/usr/bin/sim"
condor.leave_in_queue: "TRUE"
}
}
4.7.7. Coasters
Coasters are a mechanism that packages multiple swift application invocations into larger LRM jobs resulting in increased efficiency when running multiple small applications. To distinguish between the application invocations and the jobs in which Coasters package them, the terms task and job are used, respectively.
General Configuration
URL required |
maybe |
Job Manager |
"em1:em2", where em1 is an execution mechanism used to start the Coaster Service and em2 is an execution mechanism used by the Coaster Service to start jobs. If em1 requires an URL, then the URL is required. |
Staging methods |
swift, wrapper, local, service-local, shared-fs, direct |
Options
| Name | Type | Default Value | Description |
|---|---|---|---|
maxJobs |
Integer |
20 |
The maximum number of jobs that can be running at a time. |
nodeGranularity |
Integer |
1 |
If specified, the number of nodes requested for each job will be a multiple of this number |
tasksPerNode |
Integer |
1 |
The maximum number of concurrent tasks allowed to run on a node |
allocationStepSize |
[0.0, 1.0] |
0.1 |
The Coaster service allocates jobs periodically depending on the number of tasks queued. This number can be used to limit the percentage of jobs out of maxJobs that will be used in each allocation step. |
lowOverallocation |
Positive float |
10 |
Indicates how much bigger the job wall time should be in comparison to the task wall time for tasks that have a small wall time (around 1 second) |
highOverallocation |
Positive float |
1 |
Indicates how much bigger the job wall time should in comparison to the task wall time for tasks that have a very large wall time |
overallocationDecayFactor |
Positive float |
1e-3 |
Used to interpolate the "overallocation" for task wall times that are neither very large or very small. The formula used is jobWalltime = taskWalltime * ((L - H) * exp(-taskWalltime * D) + H), where L is lowOverallocation, H is highOverallocation, and D is overallocationDecayFactor. |
spread |
[0.0, 1.0] |
0.9 |
When allocating jobs, the total number of nodes to allocate can be fixed based on, for example, maximizing parallelism for all the tasks. However, the way the nodes are distributed to individual jobs can be arbitrary. This parameter controls whether nodes should be uniformly distributed among jobs (spread = 0) or if the node distribution should be as diverse as possible (spread = 1). A high spread could be useful in fitting jobs better into a cluster’s schedule. |
reserve |
Integer (seconds) |
60 |
The amount of time to add to each job’s wall time in order to prevent premature termination of tasks due to various overheads |
maxNodesPerJob |
Integer |
1 |
The maximum number of nodes that a job is allowed to have. |
maxJobTime |
"HH:MM:SS" |
- |
The maximum wall time that a job is allowed to have |
userHomeOverride |
String |
- |
A path that can be used to override the default user home directory. This may be necessary on systems on which compute nodes do not have access to the default user home directory. |
internalHostName |
String |
- |
A host name or address that can be used to initiate connections from compute nodes to the login node. Specifying this is seldom necessary. |
jobQueue |
String |
- |
The LRM queue to submit the jobs to |
jobProject |
String |
- |
A LRM project to associate the job with |
workerLoggingLevel |
"ERROR", "WARN", "INFO", "DEBUG", "TRACE", or none |
none |
If specified, the Coaster Workers produce a log file |
workerLoggingDirectory |
String |
"~/.globus/coasters" |
The directory where the worker logs will be created. This directory needs to be accessible from compute nodes. |
softImage |
String |
- |
WRITEME! |
Job Options
N/A
Example
site.condor {
execution {
type: "Condor"
}
app.sim {
executable: "/usr/bin/sim"
condor.leave_in_queue: "TRUE"
}
}
5. Debugging
5.1. Retries
If an application procedure execution fails, Swift will attempt that execution again repeatedly until it succeeds, up until the limit defined in the execution.retries configuration property.
Site selection will occur for retried jobs in the same way that it happens for new jobs. Retried jobs may run on the same site or may run on a different site.
If the retry limit execution.retries is reached for an application procedure, then that application procedure will fail. This will cause the entire run to fail - either immediately (if the lazy.errors property is false) or after all other possible work has been attempted (if the lazy.errors property is true).
With or without lazy errors, each app is re-tried <execution.retries> times before it is considered failed for good. An app that has failed but still has retries left will appear as "Failed but can retry".
Without lazy errors, once the first (time-wise) app has run out of retries, the whole run is stopped and the error reported.
With lazy errors, if an app fails after all retries, its outputs are marked as failed. All apps that depend on failed outputs will also fail and their outputs marked as failed. All apps that have non-failed outputs will continue to run normally until everything that can proceed completes.
For example, if you have:
foreach x in [1:1024] {
app(x);
}
If the first started app fails, all the other ones can still continue, and if they don’t otherwise fail, the run will only terminate when all 1023 of them will complete.
So basically the idea behind lazy errors is to run EVERYTHING that can safely be run before stopping.
Some types of errors (such as internal swift errors happening in an app thread) will still stop the run immediately even in lazy errors mode. But we all know there are no such things as internal swift errors :)
5.2. Restarts
If a run fails, Swift can resume the program from the point of failure. When a run fails, a restart log file will be left behind in the run directory called restart.log. This restart log can then be passed to a subsequent Swift invocation using the -resume parameter. Swift will resume execution, avoiding execution of invocations that have previously completed successfully. The Swift source file and input data files should not be modified between runs.
Normally, if the run completes successfully, the restart log file is deleted. If however the workflow fails, swift can use the restart log file to continue execution from a point before the failure occurred. In order to restart from a restart log file, the -resume logfile argument can be used after the Swift script file name. Example:
$ swift -resume runNNN/restart.log example.swift.
5.3. Monitoring Swift
Swift runs can be monitored for progress and resource usage. There are three basic monitors available: Swing, TUI, and http.
5.3.1. HTTP Monitor
The HTTP monitor will allow for the monitoring of Swift via a web browser. To start the HTTP monitor, run Swift with the -ui http:<port> command line option. For example:
swift -ui http:8000 modis.swift
This will create a server running on port 8000 on the machine where Swift is running. Point your web browser to http://<ip_address>:8000 to view progress.
5.3.2. Swing Monitor
The Swing monitor displays information via a Java gui/X window. To start the Swing monitor, run Swift with the -ui Swing command line option. For example:
swift -ui Swing modis.swift
This will produce a gui/X window consisting of the following tabs:
-
Summary
-
Graphs
-
Applications
-
Tasks
-
Gantt Chart
5.3.3. TUI Monitor
The TUI (textual user interface) monitor is one option for monitoring Swift on the console using a curses-like library.
The progress of a Swift run can be monitored using the -ui TUI option. For example:
swift -ui TUI modis.swift
This will produce a textual user interface with multiple tabs, each showing the following features of the current Swift run:
-
A summary view showing task status
-
An apps tab
-
A jobs tab
-
A transfer tab
-
A scheduler tab
-
A Task statistics tab
-
A customized tab called Ben’s View
Navigation between these tabs can be done using the function keys f2 through f8.
5.4. Log analysis
Swift logs can contain a lot of information. Swift includes a utility called "swiftlog" that analyzes the log and prints a nicely formatted summary of all tasks of a given run.
$ swiftlog run027
Task 1
App name = cat
Command line arguments = data.txt data2.txt
Host = westmere
Start time = 17:09:59,607+0000
Stop time = 17:10:22,962+0000
Work directory = catsn-run027/jobs/r/cat-r6pxt6kl
Staged in files = file://localhost/data.txt file://localhost/data2.txt
Staged out files = catsn.0004.outcatsn.0004.err
Task 2
App name = cat
Command line arguments = data.txt data2.txt
Host = westmere
Start time = 17:09:59,607+0000
Stop time = 17:10:22,965+0000
Work directory = catsn-run027/jobs/q/cat-q6pxt6kl
Staged in files = file://localhost/data.txt file://localhost/data2.txt
Staged out files = catsn.0010.outcatsn.0010.err